
Centos7.6环境基于Prometheus和Grafana结合钉钉机器人打造全时监控(预警)Docker容器服务系统
我们知道,奉行长期主义的网络公司,势必应在软件开发流程管理体系上具备规范意识,即代码提交有CR(CodeReview),功能测试上自动化,而功能发布讲究三板斧:灰度、监控、止血。灰度属于测试范畴,止血则是亡羊补牢,今天我们来聊聊监控,提起监控,就不得不提在DepOps(自动化运维)领域鼎鼎有名的Prometheus(普罗米修斯),有人说这个开源系统的名字怎么有点如雷贯耳啊,没错,它的名字就是取自从宙斯手中为人类夺回圣火的古希腊神明普罗米修斯,而Prometheus的Logo恰恰就是奥林匹克圣火。Prometheus主要的功能就是可以无时不刻的监控所有部署在生产环境中的服务,如果服务出现问题则会及时报警以提醒开发者。
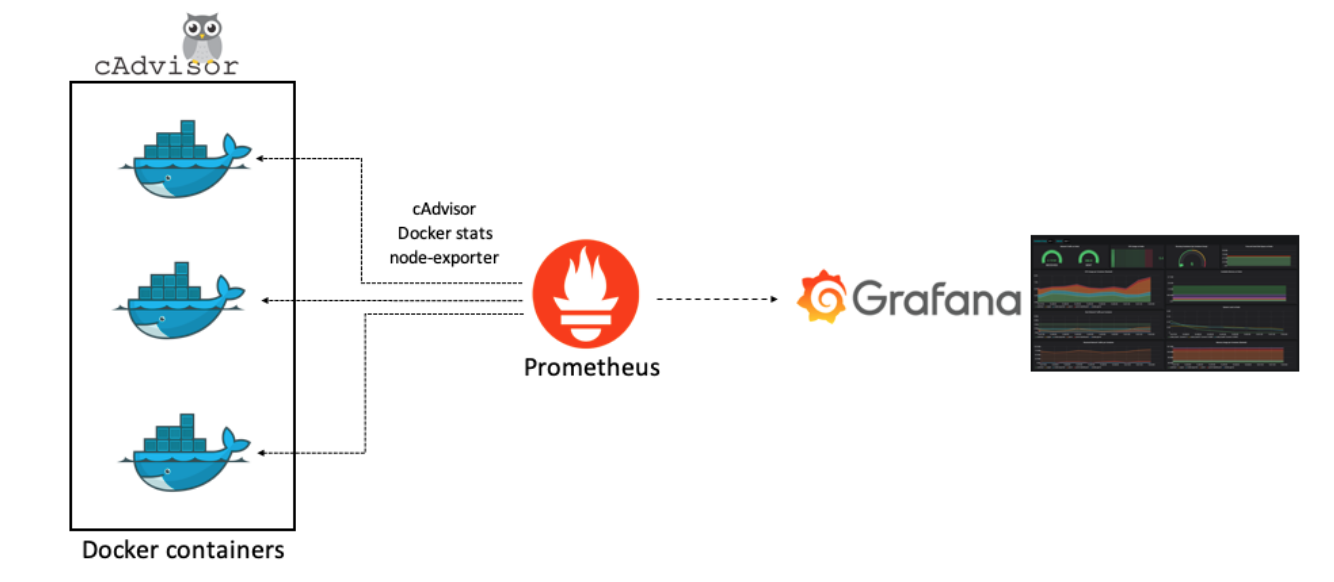
本次我们利用Docker和Prometheus以及周边的其他生态来搭建一套属于自己的全时监控告警平台,系统采用Centos7.6。
首先在系统中安装Docker:
1 | #升级yum |
安装成功后查看版本:
1 | [root@instance-53r3vagg tmp]# docker -v |
在下载镜像之前,我们需要设置一下国内源,用来提高下载速度,执行sudo vim /etc/docker/daemon.json 命令创建新文件,并添加如下代码:
1 | { |
重启Docker:
1 | sudo systemctl restart docker |
随后拉取Prometheus的Docker镜像:
1 | docker pull prom/prometheus:latest |
这里我们以监控Redis数据库为例子,所以还需要拉取redis和redis状态收集器两个镜像:
1 | docker pull redis |
分别启动redis和redis状态收集器:
启动redis:
1 | docker run -d --name redis -p 6379:6379 redis |
启动redis状态收集器
1 | docker run -d --name redis_exporter -p 9121:9121 oliver006/redis_exporter:latest --redis.addr redis://120.48.20.113:6379 |
这里redis_exporter监听服务器上的redis服务,而redis_exporter运行在9121端口上,注意redis的地址写服务器的公网ip。
运行docker ps查看服务:
1 | [root@instance-53r3vagg tmp]# docker ps |
随后创建prometheus的配置文件
1 | vim /tmp/prometheus.yml |
加入下面代码:
1 | scrape_configs: |
这里每隔5秒就获取一下服务运行信息,注意服务器地址要写公网ip,随后启动prometheus服务:
1 | docker run -d -p 9090:9090 -v /tmp/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus:latest |
此时,prometheus就运行在9090端口上,访问一下:http://120.48.20.113:9090/targets

就可以看到redis服务正在运行,与此同时,也可以查询一些参数,比如内存占用:

监控我们已经做到了,但是如果redis服务挂了怎么办,如何第一时间让研发人员知晓情况是首要课题,还在用原始的邮件通知?还记得钉钉机器人么?这里我们引入一个报警机器人,来实现24小时全时报警的功能,创建一个机器人:

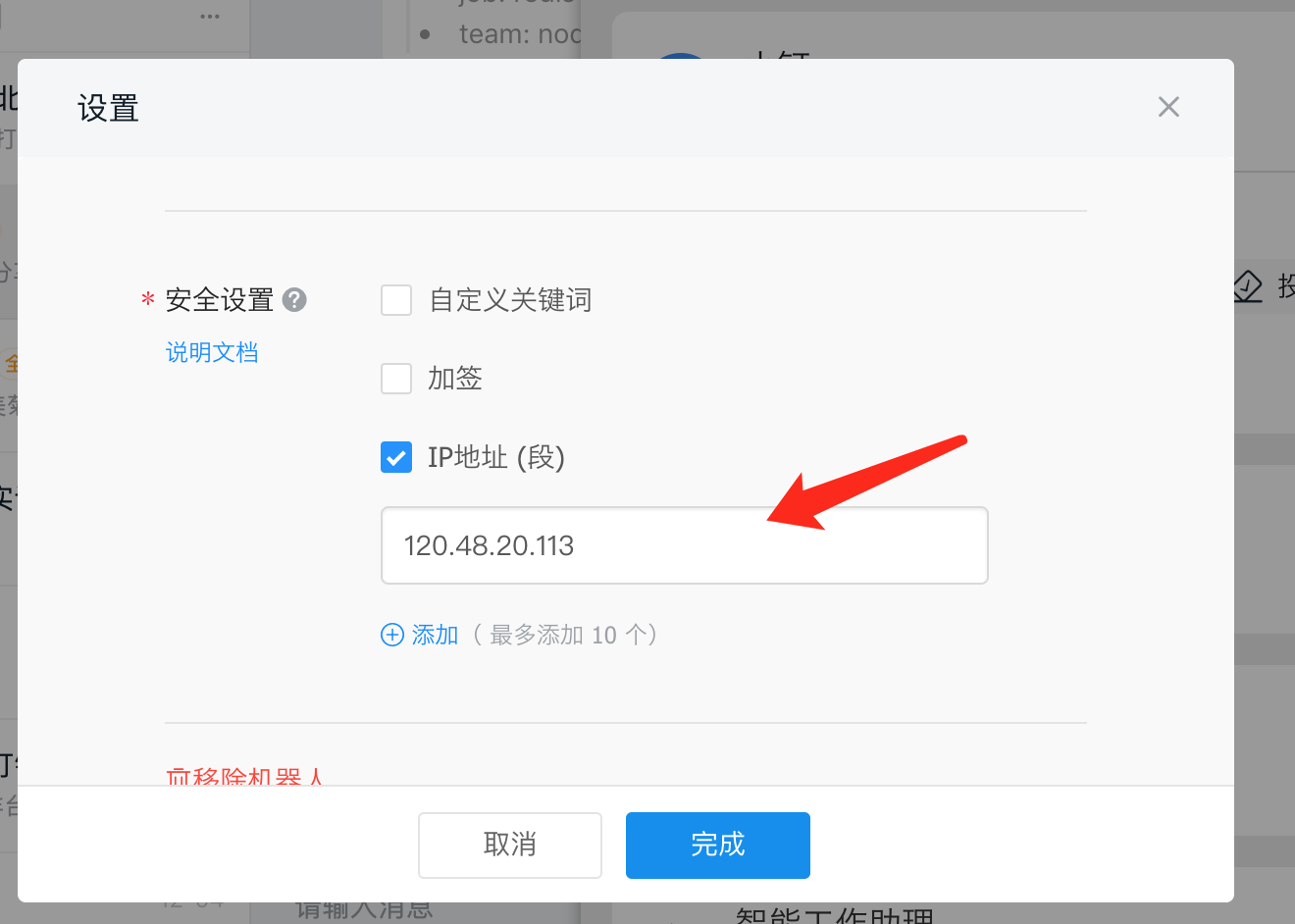
这里需要注意一点,安全设置选择ip过滤,将公网ip填入:
ok,前置操作搞定了,接下来我们继续利用Docker拉取两个镜像:
1 | docker pull prom/alertmanager:latest |
分别是prometheus的告警模块以及钉钉机器人插件,流程是如果prometheus检测到服务器异常,就会通过请求钉钉机器人的webhook地址来发送告警通知。
编写告警配置文件:
1 | vim /tmp/alertmanager.yml |
添加代码:
1 | global: |
同时编写告警规则:
1 | vim /tmp/redis.rules |
添加代码:
1 | groups: |
最后,修改一下prometheus的配置文件,将告警设置配置好:
1 | vim /tmp/prometheus.yml |
修改代码:
1 | scrape_configs: |
重启prometheus服务:
1 | docker run -d -p 9090:9090 -v /tmp/prometheus.yml:/etc/prometheus/prometheus.yml -v /tmp/redis.rules:/etc/prometheus/redis.rules prom/prometheus:latest |
注意,这里和第一次启动prometheus有所不同,这次我们通过-v挂载命令将redis.rules挂载到容器内部使用,随后启动告警服务以及钉钉插件:
启动告警模块:
1 | docker run -d --name alertmanager -p 9093:9093 -v /tmp/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager:latest |
启动钉钉插件:
1 | docker run -d -p 8060:8060 --name webhook timonwong/prometheus-webhook-dingtalk --ding.profile="webhook1=https://oapi.dingtalk.com/robot/send?access_token=钉钉token" |
注意将token替换成自己的机器人token。
再次访问http://120.48.20.113:9090/rules

可以看到告警配置已经生效了,现在我们简单模拟一下redis的宕机
1 | [root@instance-53r3vagg tmp]# docker stop redis_exporter |
prometheus监控立刻发现问题:

如果宕机持续10秒,则会立刻触发firiing(警告):

同时,钉钉机器人立刻发送信息:

整个过程滴水不漏,当然了,如果你觉得prometheus的监控界面过于简陋,可以使用Grafana将监控数据可视化:
1 | docker run -d --name prom-dashboard -p 3000:3000 |
访问地址:http://120.48.20.113:3000/
默认账号密码是admin/amdin。
导入数据:

选择prometheus

配置prometheus地址和端口:

随后就能以图形化界面来监控服务了:

结语:监控是整个项目生命周期中至关重要的一环,灾前及时预警发现故障,灾后提供详实的数据用于追查定位问题,而prometheus正是这样一个承前启后继往开来的监控宗师,区区5个镜像就可以帮助我们打造全时无死角监控预警体系。
 wechat
wechat

